
8. Attitude Determination, Control, and Sensing
8.7 Determination
authored by Dr. Zhu with major contributions from Dr. Manchester

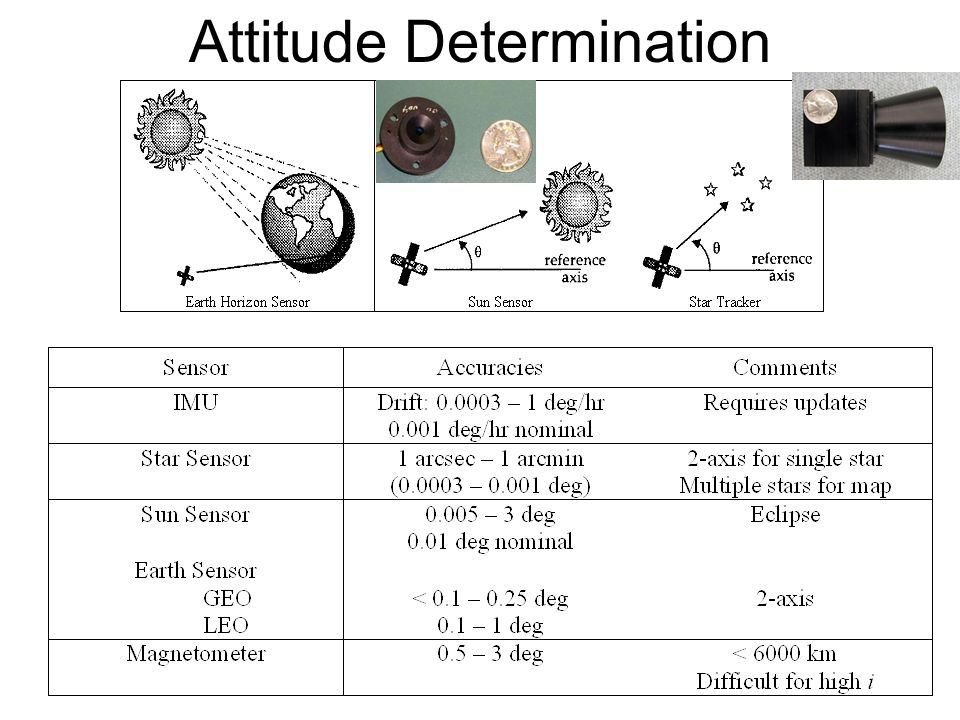
Determining attitude is the act of taking sensor measurements and calculating the spacecraft’s attitude. As I was foreshadowing before in the sensor section, we need at least two unit vectors (directions) to uniquely determine attitude. These unit vectors or directional vectors can be toward a number of reference points: the sun, the Earth’s horizon, the relative direction of Earth’s magnetic field, or a star. A star tracker can uniquely determine attitude because there are multiple stars in the camera’s field of view, offering at least those two unit vectors. The attitude determination problem is solved with a star tracker that can give us a 3DOF attitude estimate! Unfortunately, if you don’t have a star tracker or if you want to achieve a more accurate or precise attitude estimate, you will need to incorporate multiple sensor measurements together. A sun sensor, Earth sensor, or magnetometer individually can only provide one unit vector, so thus, we need to combine these types of sensor measurements to get a 3DOF attitude estimate.
There are two types of attitude determination algorithms. A lost-in-space or static determination algorithm incorporates instantaneous observations (say a sun vector and magnetic field vector at a snapshot in time) to produce an attitude. Lost-in-space implies that the spacecraft has no memory, opens its eyes or camera shutters for the first time or after a reboot, and needs to produce an initial estimate of attitude. The other type of determination algorithm comes after the initial observation when we’ve accumulated multiple sensor measurements over time. With continuous observations, we can combine past measurements and our knowledge of attitude dynamics to get an ever more precise estimate of the spacecraft’s attitude, achieving precision below the noise level of any sensor! Because of this algorithm’s ability to reject noise, we call these algorithms filters, which fall under the umbrella of determination and estimation.
This section will review common determination algorithms. There will be a LOT of math in the derivation of these algorithms. The intuition is 1) you need observations that span the 3 degrees of freedom and 2) with clever matrix manipulation, geometric relationships, and attitude representation identities, you can find an attitude representation that minimizes the error in rotating observations between an inertial and body frame. If you’re interested in implementing these algorithms, there are many papers and likely code repositories you can dig into outside this text.
TRIAD
TRIAD is one of the first attitude determination algorithms, derived in the early 60’s [Black]. This static algorithm was used for the US transit satellites, a predecessor to GPS. Say we have 2 unit vectors, known in both body and inertial frames, and are linearly independent (cannot be parallel). The goal is to find a rotation matrix from the observations,  Let’s start with this known relationship:
Let’s start with this known relationship:

We can make a 3rd linearly independent vector by taking a cross-product of our observations:


As long as  and
and  are linearly independent, V will be invertible:
are linearly independent, V will be invertible:

Matrix inverses are computationally intensive so let’s try to avoid that operator. Since V is orthogonal by definition, the inverse is also the transpose. Transposes are much simpler to take. The final, classic TRIAD solution is:

The TRIAD method is very simple to implement but! TRIAD can only handle 2 observations, doesn’t account for dynamics, and doesn’t offer “covariance” or “error bound” information. TRIAD is typically used with a sun sensor and magnetometer.

Wahba’s Problem/ Batch Estimation
What happens if we want to use more than 2 observations to improve our estimate? Say we have a batch of measurements and we want to solve the static attitude problem at a single time step with all these measurements. We define a least-squares cost function for attitude, which is a minimization problem to find the rotation that minimizes the squared error between the inertial observation and rotated body observation:

Where  are scalar weights. Weights should be inversely proportional to sensor variance to give a maximum likelihood answer.
are scalar weights. Weights should be inversely proportional to sensor variance to give a maximum likelihood answer.
To find attitude (the rotation matrix), we solve the following optimization problem:
 such that
such that 
The SO(3) constraint makes this minimization problem interesting and the solutions diverse. We will talk about three solutions: 1) convex optimization, 2) SVD method and 3) q-Method.
Convex Optimization Solution
The convex optimization solution makes use of constraints and relaxation techniques to ultimately achieve a convex optimization problem that can be solved. Let’s begin the thought process.
If we look closer at Wahba’s cost function, we can transform the squared error into a trace with a trick!

Where the trace trick is:
![x^T A y = Tr[x^T A y ]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-802842b6ac6570070cb1b1b8b28413e3_l3.png "Rendered by QuickLaTeX.com")
![= Tr[y x^T A]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-83cf771f1213e7469ec8d7a1673beb01_l3.png "Rendered by QuickLaTeX.com")
There’s a striking observation: the minimization problem or cost function is linear with respect to the rotation matrix, R! To get a solution to this linear minimization problem, we can form an intermediate variable, B, which is the attitude profile matrix. It stores the observations in the body and inertial frames over time.

We can now re-write Wahba’s problem as:
![\displaystyle{\max_{R} Tr[B \;R]}](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-e6e95e01cda7ffa4fc08726c3693784b_l3.png "Rendered by QuickLaTeX.com") such that
such that  and
and 
The minimization problem is linear but the constraints are non-convex. You can imagine that the edge of the circle are solutions for the equality constraint and the shaded region are solutions to the inequality constraint.


Non-convex optimization problems are really very hard to solve so we’d like to transform the minimization problem into a convex problem. Replacing the equality with an inequality is called “relaxation”. The new, more easily solved optimization problem is:
such that 
Because the objective is linear, we will always end up on the boundary of the solution set, satisfying the constraint with equality. This particular set up is a special type of relaxation: “tight relaxation”. Linear optimization problems with inequality constraints are solved with semidefinite programs, which are numerical solvers. There are plenty of good solvers in various computer languages and libraries, like SEDUMI in Matlab.
We just walked through the convex optimization solution for Wahba’s problem. Given multiple observations in the body and inertial frame, an optimization problem was set up and transformed into a form that can be encoded into a numerical solver. The computer then solves for the attitude, R.
SVD solution
The SVD solution makes use of singular value decomposition (SVD) of the attitude profile matrix we defined earlier. Here’s the thought process.
The rotation matrix is defined by and can be written:

Where  are mutually orthogonal unit vectors. Previously we used
are mutually orthogonal unit vectors. Previously we used  as the vectors but we need that letter for SVD, so we’re using
as the vectors but we need that letter for SVD, so we’re using  for these reference unit vectors now.
for these reference unit vectors now.
But what happens if are not mutually orthogonal, which is likely for some random measurements spacecraft typically see? Let’s revisit the attitude profile matrix:

The optimal  is the closest special-orthogonal matrix to
is the closest special-orthogonal matrix to  .
.
To do this, we use singular value decomposition:

Where  is some matrix,
is some matrix,  and
and  are orthogonal matrices, and
are orthogonal matrices, and  is a diagonal matrix. Diagonal elements of
is a diagonal matrix. Diagonal elements of  are called “singular values”,
are called “singular values”,  . SVD is like an eigendecomposition but more general. We can make a special orthogonal matrix by setting
. SVD is like an eigendecomposition but more general. We can make a special orthogonal matrix by setting 
In summary, the SVD algorithm procedure is:
- Form the attitude profile matrix, B, from measurements
- Compute the SVD of the attitude profile matrix, B

- Compute the special orthogonal matrix with the SVD components

q-Method
The q-method is named after the quaternion variable name, q. We have to reform the optimization problem to incorporate the quaternion and solve for the quaternion.
Remember the optimization problem can be reformed to a linear form from the convex optimization solution? Here it is again and with the attitude profile matrix:

![= - \; Tr[(\sum_i w_i \leftindex^B{r_i} \leftindex^N{r_i^T}) \leftindex^N{R^B} ]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-0eaae14cd6d69846211a51fe93a2bb02_l3.png "Rendered by QuickLaTeX.com")

This cost function, L, is linear with respect to the rotation matrix, R.
To incorporate the quaternion into the loss function, let’s relate the quaternion to the rotation matrix first:

Where R is the rotation matrix, I is the identity matrix, v is the vector component of the quaternion, s is the scalar component of the quaternion, and the cross product operator is in the vector superscript. This expression is a quadratic function of q.
Since  is linear and
is linear and  is quadratic,
is quadratic,  takes on the higher polynomial power and can be written as a quadratic function:
takes on the higher polynomial power and can be written as a quadratic function:

This is the ultimate form we want to craft the problem into but what does K look like?
To find out what K looks like, we need to manipulate L(R) with the use of several matrix and quaternion properties. Here’s a matrix property we will eventually use:

Here’s the quaternion identity we will use:

The rotation matrix can be transformed into this form:



Let’s plug in into :

![= - \sum_i w_i \leftindex^N{r_i^T} [ (s^2 - \underbar{v}^T \; \underbar{v})I + 2s \underbar{v}^\times + 2 \underbar{v} \; \underbar{v}^T ] \leftindex^B{r_i}](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-45a2948cb3b7a79715cb2e454a61d879_l3.png "Rendered by QuickLaTeX.com")
The goal is to factor all of the “q stuff” out to the sides:

In terms of the quaternion, Wahba’s problem is now:
 OR
OR  such that
such that 
Since ||q|| = 1, we only get to pick its direction.
The final conclusion is that  will be maximized when q is parallel to the eigenvector corresponding to the maximum eigenvalue of K.
will be maximized when q is parallel to the eigenvector corresponding to the maximum eigenvalue of K.
In summary, the q-Method algorithm procedure is:
1.Form the attitude profile matrix, B, and intermediate product, Z:
and 
2. Construct K

3. Calculate  and corresponding eigenvector
and corresponding eigenvector
4. Normalize the maximum eigenvector to obtain  . Woo! We have our quaternion as a result!
. Woo! We have our quaternion as a result!
Conclusion remarks: lots of other methods (QUEST, ESOQ, etc.) are derived from the q-Method by using tricks for solving step 3.
Kalman Filter
What if instead of a batch of measurements at one time step, you have a sequence of observations over time? This system is dynamic in that we have to account for time. It would make sense to incorporate a dynamics model to inform if your measurements are consistent with the way spacecraft dynamics are expected to propagate, right? A common solution is the Kalman filter, which is the optimal linear state estimator for a linear dynamical system.

“In statistics and control theory, Kalman filtering, also known as linear quadratic estimation (LQE), is an algorithm that uses a series of measurements observed over time, containing statistical noise and other inaccuracies, and produces estimates of unknown variables that tend to be more accurate than those based on a single measurement alone, by estimating a joint probability distribution over the variables for each timeframe. The filter is named after Rudolf E. Kálmán, one of the primary developers of its theory”. The Kalman filter has strong roots in aerospace control: It was during a visit by Kálmán to the NASA Ames Research Center that Schmidt saw the applicability of Kálmán’s ideas to the nonlinear problem of trajectory estimation for the Apollo program leading to its incorporation in the Apollo navigation computer. This Kalman filter was first described and partially developed in technical papers by Swerling (1958), Kalman (1960), and Kalman and Bucy (1961).
The Apollo computer used 2k of magnetic core RAM and 36k wire rope […]. The CPU was built from ICs […]. The clock speed was under 100 kHz […]. The fact that the MIT engineers were able to pack such good software (one of the very first applications of the Kalman filter) into such a tiny computer is truly remarkable.
— Interview with Jack Crenshaw, by Matthew Reed, TRS-80.org (2009)
To explain the Kalman filter, we need to go through a little background on probability and linear systems. Then, we’ll walk through the Kalman filter algorithm. If you’d like a different explanation for Kalman filters, I HIGHLY recommend visiting Tucker McClure’s tutorial.
Background
Notes on Expectation:
![E[f(x)] = \int_{-\infty}^{\infty} f(x) p(x) dx](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-644267b2c263d7f72a77fbc3acdf7598_l3.png "Rendered by QuickLaTeX.com")
Expectation is the value of a function weighted by the probability distribution. This expression gives the value of f(x) you would expect to see averaged over many random samples. Expectation is a linear operator:
![E[x+y] = E[x] + E[y]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-8563e0bd60057de449ba8273c2407f76_l3.png "Rendered by QuickLaTeX.com")
![E[\alpha x] = \alpha E[x]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-443d2adacb2bd8d7ff57b5a3fde83883_l3.png "Rendered by QuickLaTeX.com")
Where  is a scalar. Common examples of expectation are mean and standard deviation:
is a scalar. Common examples of expectation are mean and standard deviation:
![\mu = E[x]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-c9c220b5e8191fcf0b7b07e2e45d6e76_l3.png "Rendered by QuickLaTeX.com")
![P = E[(x-\mu)(x-\mu)^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-1e48f1aeb28516da8cca622830941357_l3.png "Rendered by QuickLaTeX.com")
Notes on Stochastic Linear Systems:
A discrete-time linear time-varying (LTV) system with additive noise has the following form:


Where measurement and process noise is normally distributed with a mean  = 0 and covariance of W and V:
= 0 and covariance of W and V:
 \quad , \quad
\quad , \quad 
Notes on Multivariate Gaussians:
In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. We care about multivariates because attitude is in 3 dimensions! The multivariate distribution is given by:

mean: ![\mu = E[x]\in \mathbb{R}^n](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-c1b57877b201dc8fe3dcedc1f8a92dc0_l3.png "Rendered by QuickLaTeX.com") , covariance:
, covariance: ![P=E[(x-\mu)(x-\mu)^T] \in S^n](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-7c933e5704c9e550c8318b865476aa57_l3.png "Rendered by QuickLaTeX.com")
Where n is the number of states.
Problem Statement
We are trying to minimize the error between the true spacecraft state and an estimate. For our problem of estimating attitude, the state is a vector of variables, which includes an attitude representation and angular velocity, typically quaternion and angular velocity:

Specifically, we are trying to minimize the mean squared error (MMSE) estimate by varying the state estimate:
![\begin{align*}\underset{\bar{x}}{\arg\min} \; E[(x-\bar{x})^T (x-\bar{x})] & = E[Tr((x-\bar{x})^T (x-\bar{x}))] \\&=Tr[P]\end{align*}](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-45867d8c81a4e84a3aa42544f82c65b2_l3.png "Rendered by QuickLaTeX.com")
This formulation is also known as “least squares” or “minimum variance”. The least squares is seen in the first line, where the quadratic is being minimized. The variance can be seen in the second line being minimized.
Another way to form the problem is to find the maximum a-posteriori (MAP) estimate. A-posteriori relates prior knowledge or observations to make predictions. We want to find the estimate that is most likely given previous observations. That problem statement is mathematically expressed:

Where x is the state estimate and y are previous measurements.
The MMSE and MAP estimate turn out to be the same for a Gaussian so we can derive the Kalman filter using either criterion.
Algorithm Solution
To implement a Kalman filter as a recursive linear MMSE estimator, we have to make the following assumptions:
- Assume we have an estimate of the state that includes measurement information up to
 :
:
![\bar{x}_{k|k} = E[x_k|y_{1...k}]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-1fcd80db4bc1201e97cd46f0954e7899_l3.png "Rendered by QuickLaTeX.com")
- Assume we know the state error covariance:
![P_{k|k} = E[(x_k-\bar{x}_{k|k})(x_k-\bar{x}_{k|k})^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-437a0f0908f3c5311d243e62405e4e5c_l3.png "Rendered by QuickLaTeX.com")
We want to update our estimate  and covariance
and covariance  to include a new measurement at time
to include a new measurement at time  .
.
The Kalman Filter can be broken into two steps:
- Prediction step:

![E[x_k w_k^T] = E[w_k x_k^T] = 0](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-3ae8ab89b3be6c7151eef7c5c1756fd4_l3.png "Rendered by QuickLaTeX.com")
- Measurement update:
Define “innovation”, :
:



The subsequent innovation covariance  is:
is:
![S_{k+1} = E[z_{k+1} z_{k+1}^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-a68144082d8080db19dd7825f9b235e4_l3.png "Rendered by QuickLaTeX.com")
![= E[(C (x_{k+1} - \bar{x}_{k+1|k}) + v_{k+1})(C (x_{k+1} - \bar{x}_{k+1|k}) + v_{k+1})^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-920f960d8191ba6f5bb27943460fed35_l3.png "Rendered by QuickLaTeX.com")
Noise  and state
and state  are uncorrelated:
are uncorrelated:
![S_{k+1} = C E[(x_{k+1} - \bar{x}_{k+1|k})(x_{k+1} - \bar{x}_{k+1|k})^T] C^T + E[v_{k+1}v_{k+1}^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-d4800702dbf3b2cd1fce566ece4dce9c_l3.png "Rendered by QuickLaTeX.com")

Innovation is the thing we feed back into the filter to correct our state estimate. The state update is then:

Covariance update is:
![P_{k+1|k+1} = E[x_{k+1} - \bar{x}_{k+1|k+1})(x_{k+1} - \bar{x}_{k+1|k+1})^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-6b1832a642a326e783597deca0b3bed9_l3.png "Rendered by QuickLaTeX.com")
![= E[x_{k+1} - \bar{x}_{k+1|k} - L_{k+1} z_{k+1})(x_{k+1} - \bar{x}_{k+1|k} - L_{k+1} z_{k+1})^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-b8ff702eb57b1ec439c75c51f0e9e0cb_l3.png "Rendered by QuickLaTeX.com")
![= E[x_{k+1} - \bar{x}_{k+1|k} - L_{k+1} (C (x_{k+1} - \bar{x}_{k+1|k}) + v_{k+1}))(x_{k+1} - \bar{x}_{k+1|k} - L_{k+1} (C (x_{k+1} - \bar{x}_{k+1|k}) + v_{k+1}))^T]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-363837d643c3ddaa5cdb9baa0df4f5c9_l3.png "Rendered by QuickLaTeX.com")
![= (I-L_{k+1}C) E[(x_{k+1} - \bar{x}_{k+1|k})(x_{k+1} - \bar{x}_{k+1|k})^T] (I-L_{k+1}C)^T + L_{k+1} E[v_{k+1}v_{k+1}^T] L_{k+1}^T](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-9f655d3d26a5e38eb5f2b0279c43f272_l3.png "Rendered by QuickLaTeX.com")

To find the Kalman Gain matrix, let’s revisit the MMSE problem:
![\underset{\bar{x}_{k+1}}{\arg\min} \; E[(x_{k+1}-\bar{x}_{k+1|k+1})^T (x_{k+1}-\bar{x}_{k+1|k+1})]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-29fd7432feb44391b5663a2c097e6bed_l3.png "Rendered by QuickLaTeX.com")
![= E[Tr((x_{k+1}-\bar{x}_{k+1|k+1})^T (x_{k+1}-\bar{x}_{k+1|k+1}))]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-44e923d3685eb679cf091354aa396eb1_l3.png "Rendered by QuickLaTeX.com")
![=Tr[P_{k+1|k+1}]](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-c84f8536e94bd69985a7ab603876c2fd_l3.png "Rendered by QuickLaTeX.com")
To find the solution of this quadratic function of  , we’re going to take the partial derivative and set it to 0, solving for: :
, we’re going to take the partial derivative and set it to 0, solving for: :![\text{set} \frac{\partial Tr[P_{k+1|k+1}] }{ \partial L_{k+1}} = 0\text{and solve for} L_{k+1}](https://pressbooks-dev.oer.hawaii.edu/epet302/wp-content/ql-cache/quicklatex.com-352e9622b2419f31e529fb5854cc32ee_l3.png "Rendered by QuickLaTeX.com")



To summarize all the juicy equations in one straightforward procedure, the Kalman Filter algorithm is as follows:
- Start with

- Predict:


- Calculate innovation and covariance:

- Calculate Kalman Gain:

- Update:


- Go back to step 2 once you get a new measurement
Concluding Remarks
This “vanilla” Kalman filter derivation applies to linear systems. If we were to extend this process to nonlinear systems, we would have to derive linear state matrices  and control input matrices
and control input matrices  with respect to time. This kind of Kalman filter is called an extended Kalman Filter (EKF). Another variant of the Kalman filter is the Unscented Kalman Filter (UKF), which estimates nonlinear dynamics where 1) fully nonlinear dynamics are propagated instead of linearized and 2) multiple points are propagated over time [TowardDataScience]. Particle filters are in the filtering family but instead of estimating with linear projections, the Particle filter does so by a sequential Monte Carlo method, which is a fancy way of saying repeated random sampling.
with respect to time. This kind of Kalman filter is called an extended Kalman Filter (EKF). Another variant of the Kalman filter is the Unscented Kalman Filter (UKF), which estimates nonlinear dynamics where 1) fully nonlinear dynamics are propagated instead of linearized and 2) multiple points are propagated over time [TowardDataScience]. Particle filters are in the filtering family but instead of estimating with linear projections, the Particle filter does so by a sequential Monte Carlo method, which is a fancy way of saying repeated random sampling.

Ever since the use of Kalman Filters in the Apollo program, they have been the industry standard in estimating spacecraft dynamics in orbit as they solve the dynamic state estimation problem. They are not computationally intensive and reject noise from sensor measurements quite effectively. Extended Kalman Filters are the most commonly used Kalman filter variant as it is the most computationally compact and efficient filter.

{kind=link}
{kind=link}